
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- ROS2 #설치 #우분투20.04 #
- gru
- Nerf
- OpenSfM
- Ceres
- ubuntu 20.04
- 블랜더
- python 코드
- 딥러닝
- 사진으로 3D 모델링 하기
- RTX3090TI
- 데이터셋 자동 생성
- 데이터셋생성
- 딥러닝 데이터셋
- RNNPose
- ConvGRU
- SfM의 의존성
- Blenderproc
- 명령어모음
- 자세추정
- 라이브러리 설치
- 머신러닝
- 데이터셋
- instant-ngp
- Unity
- Photogrammetry
- 카메라 내부파라미터 #c++
- Ceres-solver
- 6D Pose estimation
- 가상데이터셋
- Today
- Total
홍든램지의 보일러실
RNNPose 설치하고 실행해보기 본문
1. 설치
https://github.com/DecaYale/RNNPose.git
GitHub - DecaYale/RNNPose: RNNPose: Recurrent 6-DoF Object Pose Refinement with Robust Correspondence Field Estimation and Pose
RNNPose: Recurrent 6-DoF Object Pose Refinement with Robust Correspondence Field Estimation and Pose Optimization, CVPR 2022 - GitHub - DecaYale/RNNPose: RNNPose: Recurrent 6-DoF Object Pose Refin...
github.com
위 링크를 통해 터미널에서 다운받는다.
git clone https://github.com/DecaYale/RNNPose.gitRNNPose에서 언급한것 처럼 shell 스크립트를 실행하여 컴파일한다.
cd RNNPose/scripts
bash compile_3rdparty.shcompile_3rdparty.sh 에서 확인하면 python setup.py build_ext --inplace 내용이있다.
여기서 python3를 사용하는 사람은 위 명령어를 python3 setup.py build_ext --inplace로 변경하면된다.
컴파일하다 보면 약간에 오류가 있다.

위 에서 보는 것처럼 numpy 버전 문제가 있어서
필자는 virtualenv를 이용하여 가상환경을 만들어 다시 진행하였다.
아래와 같이 버전은 numpy 1.22버전을 설치한다.
pip install numpy==1.22.0
가상환경을 만들고 numpy 버전을 1.22 버전으로 변경하면 또다른 오류가 발생한다.

bashrc 에 CUDA_HOME 이라는 변수 즉 cuda의 디렉토리가 설정되어 있지 않아 생기는 오류이므로 bashrc에 추가해준다.
gedit ~/.bashrcvim, vi, nano 등의 편집기를 이용해서 수정할 수 도 있다.
export CUDA_HOME=/usr/local/cuda-11.3위 내용을 작성한 후
source ~/.bashrc위 커맨드를 통해 적용한다.

그리고 실행하며 cffi라는 모듈이 없다고 나온다.
cffi가 뭐하는 놈인지 보면
python같은 경우는 가독성이 좋으며 활용하기 쉬운 언어이긴 하지만 python으로는 모든 문제를 해결하기 어려운 실정이다. python의 구현체인 CPython은 C/C++이나 Go처럼 네이티브 코드를 생성하는 것이 아니라 바이트코드를 생성한 뒤 이를 하나하나 해석하는 인터프리터라서 속도가 느리며, Python으로 구현되지 않은 라이브러리를 이용해야 될경우가 있다. 속도가 필요한 부분은 C나 어셈블리어를 이용해서 작성하고 속도에 민감하지 않은 부분은 Python과 같은 고수준 언어를 이용해서 작성한뒤 이어붙이는 기법을 사용하는데 이러한 이종 언어간 인터페이스를 이용해 이어붙이는데 도와주는 것이 cffi 모듈이다.
cffi 모듈은 다운받아보자
pip install cffi
이후 RNNPose 경로에서
bash compile_3rdparty.sh를 실행하게 되면 아래와 같이 완료된 것을 볼 수 있다.

2.데이터 준비
모델을 실행하기 위해 학습된 결과를 실행하기 위해서는 RNNPose에서 학습했던 데이터에 대해서 확인을 해봐야한다.
데이터를 직접만들고 준비하는데에는 많은 시간이 걸리기 때문에 기존에 있는 데이터셋을 다운받는다. 다운받는링크
RNNPose 폴더 안에 EXPDATA라는 이름의 폴더를 생성한다. 생성된 폴더에 해당 데이터를 다운받을 수 있다.

20GB에 해당하는 용량은 확보하자.
압축을 풀게되면 아래와 같은 구조로 폴더가 구축된다.
VOCdevkit 같은경우는 객체의 뒷배경을 랜덤하게 조합하여 새로운 데이터셋을 만들기 위함인데 다운로드가 안되서 없다..
./EXPDATA
|──LM6d_converted
| |──LM6d_refine
| |──LM6d_refine_syn
| └──models
|──LINEMOD
| └──fuse_formatted
|──lmo
|──VOCdevkit
|──raw_data
|──init_poses
└──data_info결과적으로 아래와 같다.

또한 모델을 테스트하기 위해서는 LINEMOD 데이터셋을 학습한 결과가 있어야 하는데 결과는 이링크에서 다운받고 압축을
RNNPose/weights 경로해 해제한다.

압축해제한 결과를 보면 위와 같다.
2.실행 준비
학습된 모델을 평가하기 위해서 script에 있는 shell스크립트를 실행해주면 된다.
학습을 하기에는 무리가 있으니 평가되어 있는 모델로 실행을 한다.
RNNPose/scripts/eval.sh 에 내용을 보면 아래와 같다.
export PROJECT_ROOT_PATH=/home/RNNPose/Projects/Works/RNNPose_release
export PYTHONPATH="$PROJECT_ROOT_PATH:$PYTHONPATH"
export PYTHONPATH="$PROJECT_ROOT_PATH/thirdparty:$PYTHONPATH"
export model_dir='outputs'
seq=cat
gpu=1
start_gpu_id=0
mkdir $model_dir
train_file=$PROJECT_ROOT_PATH/tools/eval.py
config_path=/$PROJECT_ROOT_PATH/config/linemod/"$seq"_fw0.5.yml
pretrain=$PROJECT_ROOT_PATH/weights/trained_models/"$seq".tckpt
python -u $train_file multi_proc_train \
--config_path $config_path \
--model_dir $model_dir/results \
--use_dist True \
--dist_port 10000 \
--gpus_per_node $gpu \
--optim_eval True \
--use_apex False \
--world_size $gpu \
--start_gpu_id $start_gpu_id \
--pretrained_path $pretrain위 쉘 스크립트를 바로 실행하면 아래와 같이 오류가 뜬다.

따라서 PROJECT_ROOT_PATH 를 본인의 RNNPose 경로에 맞게 수정한다.

수정하게되면 위와같이 torch가 없다고 뜬다. 가상환경을 만들었기 때문에 해당하는 torch가 없어서
버전에 맞게 설치한다.
각버전은 CUDA버전에 맞게 설치하면 된다.
참고)https://pytorch.org/get-started/previous-versions/
PyTorch
An open source machine learning framework that accelerates the path from research prototyping to production deployment.
pytorch.org
필자의 CUDA 버전은 11.3으로 아래 해당하는 커맨드를 통해 설치하였다. torch 1.11 버전으로 설치하였다.
pip install torch==1.11.0+cu113 torchvision==0.12.0+cu113 torchaudio==0.11.0 --extra-index-url https://download.pytorch.org/whl/cu113
추가 필요 패키지 리스트이다. scripts/eval.sh 를 실행시키기위한 패키지는 아래 코드로 설치한다.
pip install tensorboard tensorboardX fire flow_vis opencv-python scikit-learn scikit-image pyyaml transform3d yacs open3d plyfile easydict numba kornia easydict numba kornia fvcore ioPathpython -m pip install numpy-quaternion그리고 추가적으로 apex 패키지가 필요한데 이건 아래 링크에서 다운받는 방법을 확인할 수 있다.
https://github.com/NVIDIA/apex
GitHub - NVIDIA/apex: A PyTorch Extension: Tools for easy mixed precision and distributed training in Pytorch
A PyTorch Extension: Tools for easy mixed precision and distributed training in Pytorch - GitHub - NVIDIA/apex: A PyTorch Extension: Tools for easy mixed precision and distributed training in Pyt...
github.com
그냥 pip 패키지를 통해 설치하면 아래와 같은 오류가 뜬다.
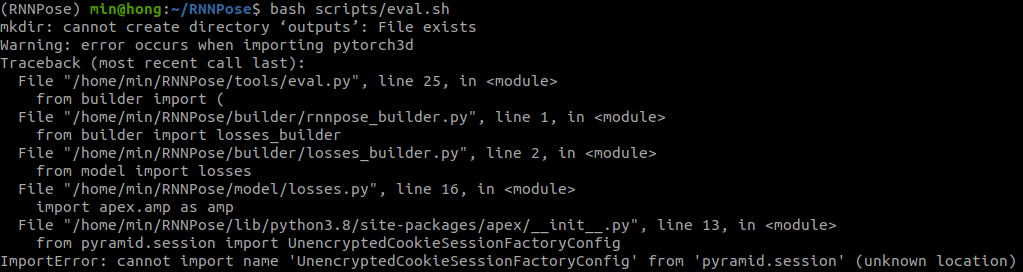
따라서 github 링크를 통해 설치하도록 한다. 설치방법은 아래와 같다.
git clone https://github.com/NVIDIA/apex
cd apex
pip install -v --disable-pip-version-check --no-cache-dir --global-option="--cpp_ext" --global-option="--cuda_ext" ./
apex의 cpp라이브러리 말고 pip 만 설치하고 싶다면 아래 커맨드를 입력한다.
pip install -v --disable-pip-version-check --no-cache-dir ./마지막으로 필요한 패키지는 pytorch3d 이다 설치방법은 아래 링크에 설명되어 있다.
https://github.com/facebookresearch/pytorch3d/blob/main/INSTALL.md
GitHub - facebookresearch/pytorch3d: PyTorch3D is FAIR's library of reusable components for deep learning with 3D data
PyTorch3D is FAIR's library of reusable components for deep learning with 3D data - GitHub - facebookresearch/pytorch3d: PyTorch3D is FAIR's library of reusable components for deep learning...
github.com
마지막으로 추가 패키지인 pytorch3d를 설치하는데 다양한 오류 및 cuda 버전때문에 문제가 생겼다.
필자는 cuda 11.3 python3.8 pytorch 1.11 에 맞는 pytorch3d 패키지를 설치하였다. 설치하기전 pytorch3d에서
CUDA를 사용하고 원본에서 빌드하는 경우 CUB 라이브러리를 사용할 수 있어야 합니다. 버전 1.10.0을 권장합니다.
라고 되어있어 아래와 같이 설치 하였다.
curl -LO https://github.com/NVIDIA/cub/archive/1.10.0.tar.gz
tar xzf 1.10.0.tar.gz
export CUB_HOME=$PWD/cub-1.10.0
pytorch3d 설치는 아래 커맨드를 이용하여 설치하였다.
pip install --no-index --no-cache-dir pytorch3d -f https://dl.fbaipublicfiles.com/pytorch3d/packaging/wheels/py38_cu113_pyt1110/download.html
이제 필요한 패키지 설치는 모두 완료하였고 실행시 필요한 파일들을 생성해야한다.
학습된 결과들로 평가하는 파이썬 코드를 실행하는 커맨드는 script/eval.sh 에 선언되어 있다. 실행하기 위해 수정이 필요하다.
#export PROJECT_ROOT_PATH=/home/RNNPose/Projects/Works/RNNPose_release
export PROJECT_ROOT_PATH=/home/min/RNNPose
export PYTHONPATH="$PROJECT_ROOT_PATH:$PYTHONPATH"
export PYTHONPATH="$PROJECT_ROOT_PATH/thirdparty:$PYTHONPATH"
export model_dir='outputs'
seq=cat
gpu=1
start_gpu_id=0
mkdir $model_dir
train_file=$PROJECT_ROOT_PATH/tools/eval.py
config_path=$PROJECT_ROOT_PATH/config/linemod/"$seq"_fw0.5.yml
pretrain=$PROJECT_ROOT_PATH/weights/trained_models/"$seq".tckpt
# --model_dir $model_dir/results \
python -u $train_file multi_proc_train \
--config_path $config_path \
--model_dir /home/min/RNNPose/outputs/results \
--use_dist True \
--dist_port 10000 \
--gpus_per_node $gpu \
--optim_eval True \
--use_apex False \
--world_size $gpu \
--start_gpu_id $start_gpu_id \
--pretrained_path $pretrain필자는 eval.sh 파일을 위 와 같이 수정하였다.
PROJET_ROOT_PATH를 본인의 경로에 맞게 설정한다.
위 내용에서 살펴볼 부분은 config_path=$PROJECT_ROOT_PATH/config/linemod/"$seq"_fw0.5.yml 이다.
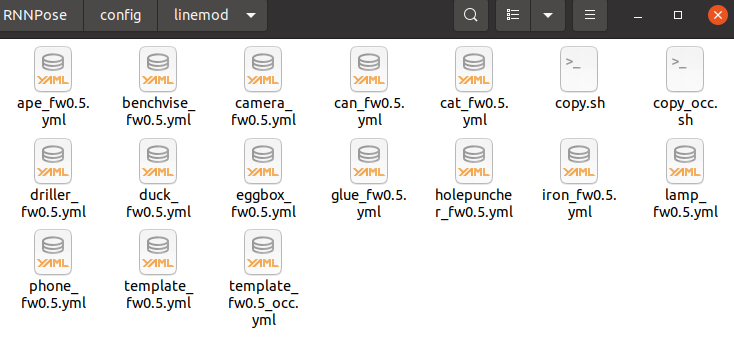
RNNPose/config/linemod 폴더를 확인하면 아래 사진과 같다.
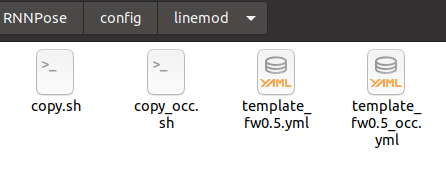
eval.sh 내용에서 사용하고자하는 파일은 seq = cat 이기 때문에 cat_fw0.5.yml 파일 이란것을 알수 있다.
하지만 해당 파일이 없기 때문에 생성해 줘야한다. 생성하기 위해서는 copy.sh 쉘 스크립트를 이용해야하며 template파일의 내용을 자신의 경로에 맞게 수정해야한다.
우선 template 파일을 수정해보자.
vars:
input_h: &input_h
320
input_w: &input_w
320
batch_size: &batch_size
1
descriptor_dim: &descriptor_dim
32
correspondence_radius_threshold: &correspondence_radius_threshold
0.01 #0.04
seq_name: &seq_name
["SEQ_NAME"]
BASIC:
zoom_crop_size: [240,240]
model:
input_h: *input_h
input_w: *input_w
batch_size: *batch_size
seq_len: 2
network_class_name: RNNPose
descriptor_net:
module_class_name: HybridFeaNet
keypoints_detector_2d:
input_dim: 3
descriptor_dim: *descriptor_dim
remove_borders: 4
normalize_output: True
keypoints_detector_3d:
#KPCONV configurations
num_layers: 4
KP_extent: 2.0
batch_norm_momentum: 0.02
use_batch_norm: true
in_points_dim: 3
fixed_kernel_points: 'center' #['center', 'verticals', 'none']
KP_influence: 'linear'
aggregation_mode: 'sum' #['closest', 'sum']
modulated: false
first_subsampling_dl: 0.025
conv_radius: 2.5
deform_radius: 5
in_features_dim: 1 #3
first_feats_dim: 128
num_kernel_points: 15
final_feats_dim: *descriptor_dim #256 #32
normalize_output: True
gnn_feats_dim: 128 #256
context_fea_extractor_3d:
#KPCONV configurations
num_layers: 4
KP_extent: 2.0
batch_norm_momentum: 0.02
use_batch_norm: true
in_points_dim: 3
fixed_kernel_points: 'center' #['center', 'verticals', 'none']
KP_influence: 'linear'
aggregation_mode: 'sum' #['closest', 'sum']
modulated: false
first_subsampling_dl: 0.025
conv_radius: 2.5
deform_radius: 5
in_features_dim: 1 #3
first_feats_dim: 128
num_kernel_points: 15
final_feats_dim: 256 #*descriptor_dim #256 #32
normalize_output: False
gnn_feats_dim: 128 #256
motion_net:
IS_CALIBRATED: True
RESCALE_IMAGES: False
ITER_COUNT: 4
RENDER_ITER_COUNT: 3 #2 #1 #3
TRAIN_RESIDUAL_WEIGHT: 0 #0.1
TRAIN_FLOW_WEIGHT: 0.5 #0.1 #1
TRAIN_REPROJ_WEIGHT: 0
OPTIM_ITER_COUNT: 1
FLOW_NET: 'raft'
SYN_OBSERVED: False
ONLINE_CROP: True
raft:
small: False #True
fea_net: "default"
mixed_precision: True
# pretrained_model: "/mnt/workspace/datasets/weights/models/raft-small.pth"
# pretrained_model: "/mnt/workspace/datasets/weights/models/raft-chairs.pth"
pretrained_model: "/home/min/RNNPose/weights/models/raft-chairs.pth"
input_dim: 3
iters: 1
loss:
metric_loss:
type: "normal"
pos_radius: *correspondence_radius_threshold # the radius used to find the positive correspondences
safe_radius: 0.02 #0.13
pos_margin: 0.1
neg_margin: 1.4
max_points: 256
matchability_radius: 0.06
weight: 0.001
saliency_loss:
loss_weight: 1
reg_weight: 0.01
geometric_loss:
loss_weight: 1
reg_weight: 0.5 #0.1
train_config:
optimizer:
adam_optimizer:
learning_rate:
one_cycle:
lr_maxs: []
lr_max: 0.0001 #
moms: [0.95, 0.85]
div_factor: 10.0
pct_start: 0.01 #0.05
amsgrad: false
weight_decay: 0.0001
fixed_weight_decay: true
use_moving_average: false
steps: 200000
steps_per_eval: 10000
loss_scale_factor: -1
clear_metrics_every_epoch: true
train_input_reader:
dataset:
dataset_class_name: "LinemodDeepIMSynRealV2"
# info_path: ["/home/RNNPose/Projects/Works/RNNPose_release/EXPDATA/data_info/deepim/linemod_orig_deepim.info.train", "/home/RNNPose/Projects/Works/RNNPose_release/EXPDATA/data_info/deepim/linemod_syn_deepim.info.train",
# "/home/RNNPose/Projects/Works/RNNPose_release/EXPDATA/data_info/linemod_fusesformatted_all10k_deepim.info.train",
# ]
# root_path: ["/home/RNNPose/Projects/Works/RNNPose_release/EXPDATA/LM6d_converted/LM6d_refine", "/home/RNNPose/Projects/Works/RNNPose_release/EXPDATA/LM6d_converted/LM6d_refine_syn",
# "/home/RNNPose/Projects/Works/RNNPose_release/EXPDATA/LINEMOD/fuse_formatted/"
# ]
info_path: ["/home/min/RNNPose/EXPDATA/data_info/deepim/linemod_orig_deepim.info.train", "/home/min/RNNPose/EXPDATA/data_info/deepim/linemod_syn_deepim.info.train",
"/home/min/RNNPose/EXPDATA/data_info/linemod_fusesformatted_all10k_deepim.info.train",
]
root_path: ["/home/min/RNNPose/EXPDATA/LM6d_converted/LM6d_refine", "/home/min/RNNPose/EXPDATA/LM6d_converted/LM6d_refine_syn",
"/home/min/RNNPose/EXPDATA/LINEMOD/fuse_formatted/"
]
model_point_dim: 3
max_points: 20000
seq_names: *seq_name
batch_size: *batch_size
preprocess:
correspondence_radius_threshold: *correspondence_radius_threshold
num_workers: 3
image_scale: 1
crop_param:
rand_crop: false
margin_ratio: 0.85
output_size: *input_h
crop_with_init_pose: True
eval_input_reader:
dataset:
dataset_class_name: "LinemodDeepIMSynRealV2"
# info_path: ["/home/RNNPose/Projects/Works/RNNPose_release/EXPDATA/data_info/linemod_posecnn.info.eval" ]
# root_path: ["/home/RNNPose/Projects/Works/RNNPose_release/EXPDATA/LM6d_converted/LM6d_refine" ]
info_path: ["/home/min/RNNPose/EXPDATA/data_info/linemod_posecnn.info.eval" ]
root_path: ["/home/min/RNNPose/EXPDATA/LM6d_converted/LM6d_refine" ]
model_point_dim: 3
max_points: 20000
seq_names: *seq_name
batch_size: *batch_size
preprocess:
correspondence_radius_threshold: *correspondence_radius_threshold
num_workers: 3
image_scale: 1
crop_param:
rand_crop: false
margin_ratio: 0.85 #0.5
output_size: *input_h #
crop_with_init_pose: True전체 내용에서 수정할 부분은
raft:
small: False #True
fea_net: "default"
mixed_precision: True
# pretrained_model: "/mnt/workspace/datasets/weights/models/raft-small.pth"
# pretrained_model: "/mnt/workspace/datasets/weights/models/raft-chairs.pth"
pretrained_model: "/home/min/RNNPose/weights/models/raft-chairs.pth"이부분으로 model에 관련 weight경로를 수정하는 것이다.
해당 위치를 본인의 경로에 맞게 수정한다. 또한 해당 weight는 https://github.com/princeton-vl/RAFT 에서 찾을수 있다.
위 깃허브 페이지에서 링크를 걸어둔 곳 구글드라이브 저장소는 아래 링크이다.
https://drive.google.com/drive/folders/1sWDsfuZ3Up38EUQt7-JDTT1HcGHuJgvT
models - Google Drive
이 폴더에 파일이 없습니다.이 폴더에 파일을 추가하려면 로그인하세요.
drive.google.com
위 모델 weight를 RNNpose/weights/models/에 해당하는 경로에 다운받는다. 사진은 아래와 같다.
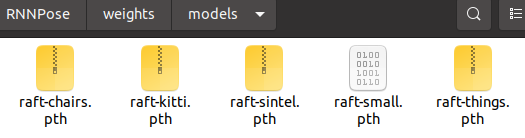
다음으로 수정할 부분은 train_input_reader 이다. 아래 경로를 수정하여 하였다.
train_input_reader:
dataset:
dataset_class_name: "LinemodDeepIMSynRealV2"
# info_path: ["/home/RNNPose/Projects/Works/RNNPose_release/EXPDATA/data_info/deepim/linemod_orig_deepim.info.train", "/home/RNNPose/Projects/Works/RNNPose_release/EXPDATA/data_info/deepim/linemod_syn_deepim.info.train",
# "/home/RNNPose/Projects/Works/RNNPose_release/EXPDATA/data_info/linemod_fusesformatted_all10k_deepim.info.train",
# ]
# root_path: ["/home/RNNPose/Projects/Works/RNNPose_release/EXPDATA/LM6d_converted/LM6d_refine", "/home/RNNPose/Projects/Works/RNNPose_release/EXPDATA/LM6d_converted/LM6d_refine_syn",
# "/home/RNNPose/Projects/Works/RNNPose_release/EXPDATA/LINEMOD/fuse_formatted/"
# ]
info_path: ["/home/min/RNNPose/EXPDATA/data_info/deepim/linemod_orig_deepim.info.train", "/home/min/RNNPose/EXPDATA/data_info/deepim/linemod_syn_deepim.info.train",
"/home/min/RNNPose/EXPDATA/data_info/linemod_fusesformatted_all10k_deepim.info.train",
]
root_path: ["/home/min/RNNPose/EXPDATA/LM6d_converted/LM6d_refine", "/home/min/RNNPose/EXPDATA/LM6d_converted/LM6d_refine_syn",
"/home/min/RNNPose/EXPDATA/LINEMOD/fuse_formatted/"
]또한 eval_input_reader 내용도 경로에 맞게 수정하였다.
eval_input_reader:
dataset:
dataset_class_name: "LinemodDeepIMSynRealV2"
# info_path: ["/home/RNNPose/Projects/Works/RNNPose_release/EXPDATA/data_info/linemod_posecnn.info.eval" ]
# root_path: ["/home/RNNPose/Projects/Works/RNNPose_release/EXPDATA/LM6d_converted/LM6d_refine" ]
info_path: ["/home/min/RNNPose/EXPDATA/data_info/linemod_posecnn.info.eval" ]
root_path: ["/home/min/RNNPose/EXPDATA/LM6d_converted/LM6d_refine" ]이후 template 경로에서 아래와 같은 커맨들르 입력한다.
~/RNNPose/config/linemod$ bash copy.sh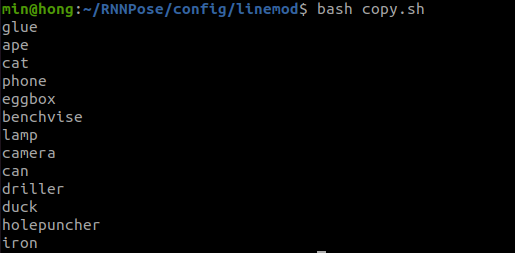
입력하게되면 위와 같은 결과를 얻을 수 있으며 LINEMOD데이터셋의 해당하는 오브젝트와 관련된 yml 파일을 얻을 수 있다.
마지막으로 RNNPose에 thirdparty에 해당하는 cpp파일을 python object를 만들어줘야 tool폴더에 있는 python파일을 아무 이상없이 시행할 수 있다.
아래와 같이 해당 경로로 들어가 컴파일을 진행하면 된다.
~/RNNPose/thirdparty/kpconv/cpp_wrappers$ bash compile_wrappers.sh이제 모든 준비가 완료 되었으며 실행을 해보자. 아래와 같이 실행한다.
~/RNNPose$ bash scripts/eval.sh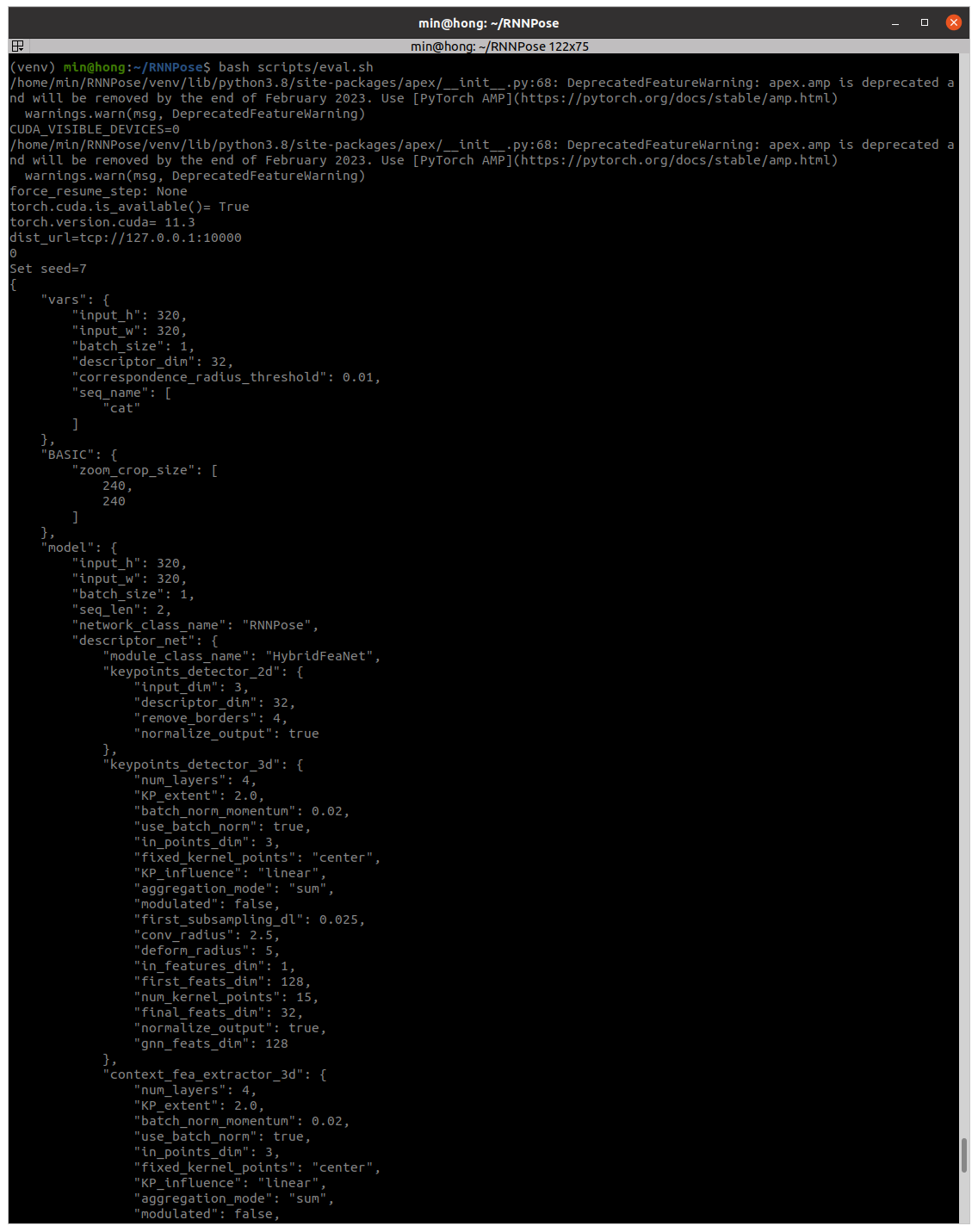
위와 같이 실행되면서 각 평가지표에 대한 정보를 도출한다. 이상으로 RNNPose 설치하고 실행하는 전과정을 적성해보았다.
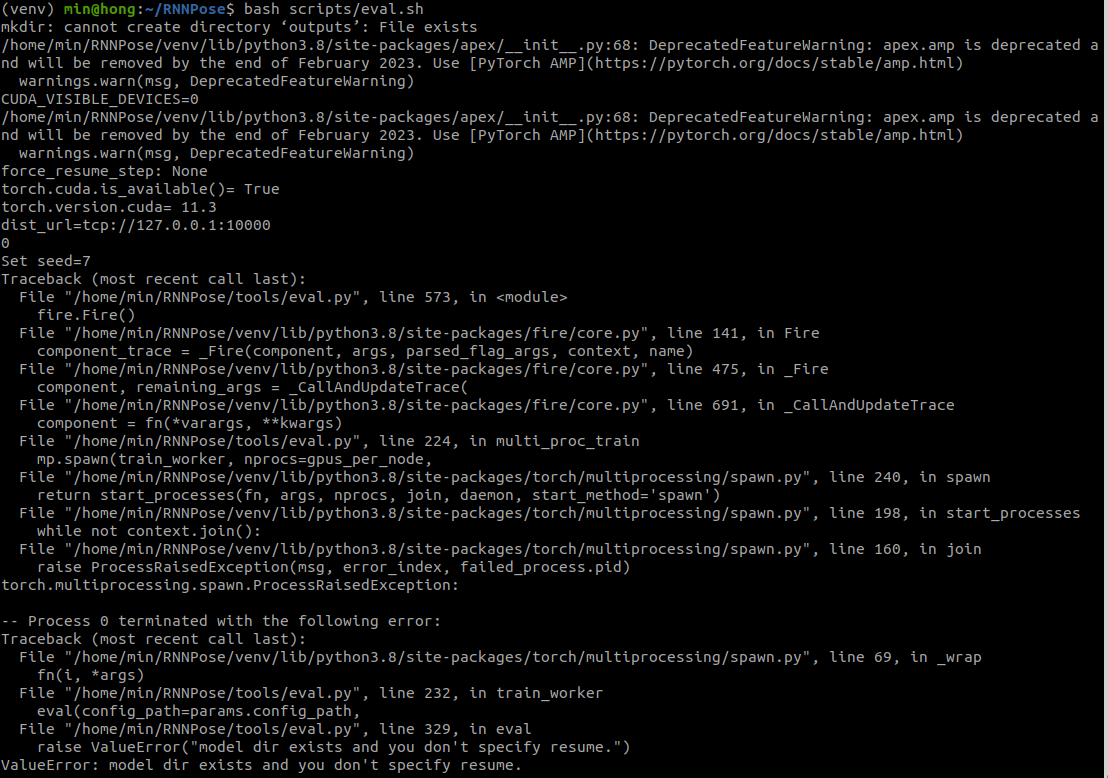
주의
실행하기전 참고로 RNNPose 폴더 안에 output 폴더가 있다면 삭제하고 진행하자 삭제하지않고 진행하면 아래와 같은 오류가 뜬다.
'AI 와 딥러닝' 카테고리의 다른 글
| ConvGRU란 무엇인가 (0) | 2023.04.06 |
|---|---|
| blenderproc를 이용한 블렌더 assets 다운로드 (0) | 2023.03.16 |
| 대규모 데이터셋을 위한 BlenderProc (0) | 2023.03.13 |
| Instant-ngp 설치 및 사전 준비하기! (0) | 2023.03.13 |
| 카메라 내부파라미터와 cpp, python 코드 (0) | 2023.03.08 |


